

Recently, the world of NLP (Natural Language Processing) has taken the world by storm. ChatGPT and BERT are one of the most famous and influential NLP models. BERT(Bidirectional Encoder Representations from Transformers) is an open-source neural network technique for Natural Language Processing and is developed by the large tech giant, Google.
ChatGPT, on the other hand, is a sibling model of Instruct GPT which has been developed by Open AI and is an advanced language model based on top of GPT 3.5 and GPT 4.0. This language model can answer your queries and help in completing some of your minor tasks. In this article, we will be taking a brief look at the similarities and differences between these two models.
What is BERT?
BERT is an acronym for Bidirectional Encoder Representations from Transformers and is a pre-trained NLP model based on the transformer architecture. The transformer architecture is a machine-learning architecture that contains sub-modules known as transformer blocks. These blocks contain the self-attention mechanism and the position-wise -feed-forward neural network.
This transformer architecture behind Google’s BERT enables it to understand the context of the input text by processing the text from both sides simultaneously. The BERT model understands the content of the word by looking at the words before and after it. Google has used the latest Cloud TPUs to build advanced models which serve more relevant results quickly.
People can apply BERT models for getting ranked and featured snippets in Search as this model gives better performance in most of the NLP tasks. This model is pre-trained on large loads of text data which enables it to learn language patterns and structures from the input. The language model can understand natural language with a more human touch because of its pre-training.
This model is beneficial for detailed searches and queries which have prepositions like ‘for’ and ‘to’ as it can understand the context of the words in these searches. To understand the model better, let’s have a look at an example:
Example- Establishing relation Between Words
Let’s say, there is a Brazilian traveler who wants a visa for traveling to the USA and he types the query “2019 brazil traveler to usa need a visa”. The previous models used by Google were not able to understand the flow of this command and returned something irrelevant, but the BERT model establishes a relationship and connection with all the words around the preposition ‘to’ to produce relevant and accurate results.
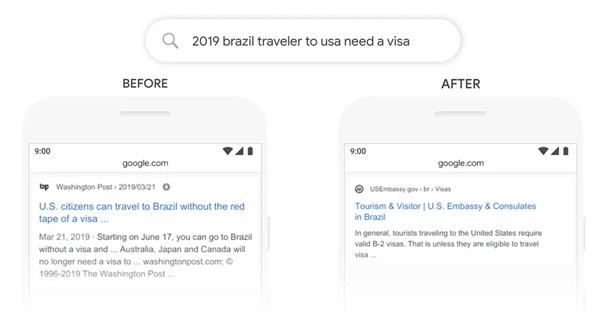
The above image shows the before and after results after using Google’s BERT model.
What is Chat GPT?
Chat GPT is an NLP model which also uses transformer architecture and deep learning algorithms to generate human-like responses to users’ queries. The model is trained in Reinforcement learning from Human feedback which makes it able to understand the context of the query and then reply accordingly.
The initial model was trained by using supervised fine-tuning in which AI trainers had to converse from both sides ie user and AI. The trainers had model-written suggestions which helped them to create their responses and create a dataset. Later, this dataset and a previous model’s database were combined for creating the dialogue format ChatGPT.
Similar to BERT, Chat GPT is also pre-trained on massive amounts of data which makes it possible to generate strikingly accurate results by just using small prompts. This model does not rely on any types of fixed patterns or rules for generating fluent text which makes it a very powerful choice for creating chatbots and virtual assistants.
In 2023, Open AI announced its latest update to the GPT model which was GPT4. GPT 4 is more creative and can generate, edit, and iterate on technical writing tasks. One of the major problems that Chat GPT had was that it was able to handle a very less amount of text, this problem was solved with GPT 4 which can handle 25000 words which makes it very useful for long-term content.
This updated model produces more reasonable output in comparison with ChatGPT. Here is an image that demonstrates the output of the same query in GPT 4 and Chat GPT.

Some Disadvantages of a Large Model
These NLPs are indeed powerful but come with their own set of disadvantages which can be:
Lack of Authenticity: While the response may seem legitimate, it is very difficult to determine the authenticity of the output given by these generative models.
Sensitive to Prompts: These models can give different answers for the same types of prompts with just some tweaks. Let’s say we give a particular prompt and the model denies the answer but changing some words and tweaking the prompt to the slightest can make the model answer the same question.
Biased Answers: Language models can be biased to the data that they are trained on, which makes their answers look a bit repetitive.
Difference between BERT and ChatGPT
Now that we know about both of the NLP models we can draw a line that can distinguish both of them based on what they do and who are their users.
Level of Customization
ChatGPT is trained on specific models which can have multiple use cases which makes it highly customizable whereas, the BERT is trained on a more general-purpose model which makes it less customizable than ChatGPT.
Text Processing
Google’s BERT uses bidirectional transformers to understand the context of the input text, whereas ChatGPT uses general transformer architecture to process the text and give a contextual-based response.
Type of Architecture and Model Size
Google’s BERT models can have different variations and all of them have different sizes but the basic BERT model has 12 transformer layers and 110 million parameters along with 768 self-attention training heads. BERT has another variation of the model named, BERT large which has 24 transformer layers and 340 parameters along with 1024 self-attention training heads. Chat GPT on the other hand, is a large model which has 96 transformer layers and 175 billion parameters. GPT 4, the latest update has almost 100 trillion parameters.
Access to the Models
BERT is open source which means that anyone can train it to create their application. Google says that it should take about 30 minutes to train their application while using a single Cloud TPU or several hours if you’re using a single GPU. Open AI, on the other hand, has many variations of the GPT models some of which are free to use and some are paid ones.
Objective of Training
The objectives behind the creation of both of these models are different. BERT was pre-trained on large amounts of data and later fine-tuned for performing specific downstream tasks. It is used for Natural Language Understanding (NLU) and Natural Language Generation (NLG). Chat GPT was created for more human-like interactions and responses in a conversational way. It is also fine-tuned using reinforced learning and trained using human feedback.
Real World Application
Both of these models have something different to offer, BERT being the model which focuses on language understanding and uses its bidirectional transformers to understand the left and right context. ChatGPT on the other hand, is more focused on generating and understanding conversational text and its generative transformers allow it to remember the context of the conversation and produce the output based on the context.
Conclusion
In the huge world of deep learning and NLP (Natural Language Processing), Google’s BERT and Open AI’s Chat GPT are among the most powerful models in their specific use cases. Both of these models are similar as both of them use transformer architecture along with pre-training techniques to understand general patterns for language and then produce a human-like output. After understanding the similarities and differences between both these models you can decide and choose a model that fits your particular use case.